


The depth-first-search algorithm is used a lot in algorithms where it’s necessary to traverse through nodes. In day-to-day work, this algorithm is very likely to not be used though. However, LinkedList uses the concepts of graphs.
But before going through the DFS (Depth-First-Search) algorithm, I highly recommend you understand and go through the following articles that explain the graph data structure, tree data structure, and stack data structure.
To really understand the depth-first-search algorithm it’s also necessary to master recursion. To do so, you can go through the following article that explains in detail recursion with Java.
Let’s use the following graph to traverse using the depth-first-search algorithm.
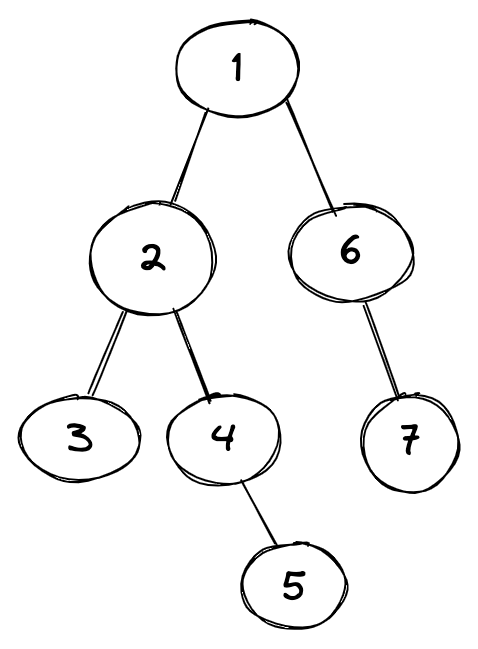
To represent the above graph we will use the following classes:
import java.util.ArrayList;
import java.util.List;
public class Node {
Object value;
private List adjacentNodes = new ArrayList();
private boolean visited;
public Node(Object value) {
this.value = value;
}
public void addAdjacentNode(Node node) {
this.adjacentNodes.add(node);
}
public List getAdjacentNodes() {
return adjacentNodes;
}
public Object getValue() {
visited = true;
return value;
}
public boolean isVisited() {
return visited;
}
}
Now let’s populate this graph with the same data from the diagram above:
public class GraphMock {
public static Node createPreorderGraphMock() {
Node rootNode = new Node(1);
Node node2 = new Node(2);
Node node3 = new Node(3);
Node node4 = new Node(4);
Node node5 = new Node(5);
Node node6 = new Node(6);
Node node7 = new Node(7);
rootNode.addAdjacentNode(node2);
node2.addAdjacentNode(node3);
node3.addAdjacentNode(node4);
node4.addAdjacentNode(node5);
rootNode.addAdjacentNode(node6);
rootNode.addAdjacentNode(node7);
return rootNode;
}
}
Preorder Traversal
The preorder graph traversal means that we will start from the root, then will traverse to the left and right subtrees.
Recursive Preorder Traversal without Lambda
Let’s see first how to traverse recursively without the use of lambda:
public class DepthFirstSearchPreorder {
public static void main(String[] args) {
Node rootNode = GraphMock.createPreorderGraphMock();
dfsRecursive(rootNode);
}
public static void dfsRecursiveWithoutLambda(Node node) {
System.out.print(node.getValue() + " ");
for (Node eachNode : node.getAdjacentNodes()) {
if (!eachNode.isVisited()) {
dfsRecursiveWithoutLambda(eachNode);
}
}
}
}
Output: 1 2 3 4 5 6 7
Notice in the code above that we first ask if the node was not visited and then invoke the dfsRecursiveWithoutLambda method recursively. The methods are stacked into the memory heap. The LIFO (Last-in First-Out) approach is used. This means that the last invoked method will be the first to be fully executed.
Recursive Preorder Traversal with Lambda
Let’s now traverse the data from the graph above using lambda:
import fundamentals.graph.Node;
public class DepthFirstSearchPreorder {
public static void main(String[] args) {
Node rootNode = GraphMock.createPreorderGraphMock();
dfsRecursive(rootNode);
}
public static void dfsRecursive(Node node) {
System.out.print(node.getValue() + " ");
node.getAdjacentNodes().stream()
.filter(n -> !n.isVisited())
.forEach(DepthFirstSearchPreorder::dfsRecursive);
}
}
Output: 1 2 3 4 5 6 7
As you can see in the code above, we are using the recursion technique. We traverse through the adjacent (neighbor) nodes filtering the nodes that were already visited. We are also invoking the dfsRecursive method recursively which will basically stack up the methods in a stack and will pop them out as soon as there isn’t any other adjacent node to be traversed.
Preorder with Looping
Doing the depth-first-search algorithm without recursion is more complex but still possible. Let’s see how is the code:
// Omitted class code
public static void dfsNonRecursive(Node node) {
Stack stack = new Stack();
Node currentNode = node;
stack.push(currentNode);
while (!stack.isEmpty()) {
currentNode = stack.pop();
if (!currentNode.isVisited()) {
for (int i = currentNode.getAdjacentNodes().size() - 1; i >= 0; i--) {
stack.push(currentNode.getAdjacentNodes().get(i));
}
System.out.print(currentNode.getValue() + " ");
}
}
}
Output: 1 2 3 4 5 6 7
Notice that the code above is not very intuitive. We have to iterate the child elements of each node in the reverse order and then put the elements into a stack. However, it’s important to show this code to prove that what can be done recursively can also be done iteratively.
Postorder Traversal
The postorder traversal will start from the leaf nodes in the left subtree until all the left subtree nodes are visited. Then the same will happen in the right subtree, and finally, the root will be printed.
Recursive Postorder traversal without Lambdas
Let’s see first how to do that without lambdas:
public class DepthFirstSearchPostorder {
public static void main(String[] args) {
dfsRecursive(GraphMock.createGraphMock());
}
public static void dfsRecursive(Node node) {
for (Node eachNode : node.getAdjacentNodes()) {
if (!eachNode.isVisited()) {
dfsRecursive(eachNode);
}
}
System.out.print(node.getValue() + " ");
}
}
Output: 5 4 3 2 7 6 1
Recursive Postorder traversal with Lambda
Now let’s see the postorder traversal with lambda:
// Omitted class code
public static void dfsRecursiveWithLambda(Node node) {
node.getAdjacentNodes().stream()
.filter(n -> !n.isVisited())
.forEach(DepthFirstSearchPostorder::dfsRecursiveWithLambda);
System.out.print(node.getValue() + " ");
}
Output: 5 4 3 2 7 6 1
Notice in the code above that the code from the preorder graph traversal is very similar. We only changed the place where the node is being printed which is after the recursive invocation.
Postorder traversal with looping
Now, to see the post-order traversal within a looping it’s more suitable to use a Binary Tree as a data structure. If we use a graph that can have more than two children the algorithm will be unnecessarily complex for this example.
Therefore, let’s see how to do the post-order depth-first-search algorithm without recursion:
// Omitted class code
public static void dfsNonRecursive(TreeNode root) {
Stack stack = new Stack();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode current = stack.peek();
var isLeaf = current.left == null && current.right == null;
if (isLeaf) {
TreeNode node = stack.pop();
System.out.print(node.value + " ");
} else {
if (current.right != null) {
stack.push(current.right);
current.right = null;
}
if (current.left != null) {
stack.push(current.left);
current.left = null;
}
}
}
}
Output: 5 4 3 2 7 6 1
Code analysis:
Notice in the code above that we will only show the node’s data if it’s the leaf node. Which is exactly what we need. Another important point is that we insert data into the stack first from a right node and then from the left node.
The stack will push the inserted node as the first element of the stack. Since in the postorder traversal we want to print first the left subtree, that will work perfectly. Another crucial detail here is that we are changing the state of the right and left nodes and that must be done! If we don’t change the state of those nodes the nodes coming before the leaf node will never be printed. That’s because we only print leaf nodes!
If we don’t want to change the state of our nodes, the code would be a little bit more complicated. But it’s not really necessary to know all the types of algorithms with graphs. We need to know the principles instead to be able to understand and solve common algorithms we might face in an interview or even on day-to-day tasks.
Inorder Traversal
The inorder traversal will first print the left subtree, then the root, and finally the right subtree.
Recursive In-order Traversal
Similarly to the postorder traversal, it’s more suitable to use this algorithm with a binary tree. By using recursion, the algorithm is much simpler. Let’s see the code example with recursion first:
public class DepthFirstSearchInorder {
public static void main(String[] args) {
dfsRecursive(TreeMock.createTreeMock());
}
public static void dfsRecursive(TreeNode node) {
if (node != null) {
dfsRecursive(node.left);
System.out.print(node.value + " ");
dfsRecursive(node.right);
}
}
}
Output: 3 2 4 5 1 6 7
Code analysis:
In the code above, we first have to check if the node is different than null to avoid a NullPointerException. Then we traverse the left nodes first and then methods are stacked up recursively. Let’s see in detail what happens when invoking those methods recursively.
We start from the root, which is node 1. Then we invoke the method recursively to the left node, then we are in node 2. Then we invoke again the method recursively with the left node which is 3 now. But node 3 doesn’t have either left or right nodes, therefore, the base condition from the recursive method is fulfilled because the next left or right node will be null.
Now the methods will start being popped out from the stack. The first one to be popped out is node 3. Now we go back to node 2. In node 2 we will continue the method execution to print the value of 2 and then will invoke the right node. The right node from 2 is node 4. Then another recursive call is made with node 4 firstly trying to invoke the left node but this one will be null. Therefore, the method execution will continue.
In node 4 we only have the right node. Therefore, the number 4 will be printed and the right 5 is invoked. Node 5 doesn’t have a left or right node. Therefore the method from node 5 will be popped out of the stack and the number 5 will be printed.
Then, the method invocation will go back to the root node and pretty much the same on the right side.
To summarize this process, let’s see the order in the nodes are invoked and printed:
1 -> 2 -> 3 -> null -> prints 3 -> null -> prints 2 -> 4 -> null -> prints 4 -> prints 5 -> null -> 5 -> prints 1 -> prints 6 -> null -> 6 -> prints 7 -> null -> 7
In-order Traversal with Looping
As mentioned before, all that is made using recursion can also be made with looping. Therefore, let’s see how to implement the inorder traversal by using looping:
// Omitted class code
public static void dfsNonRecursive(TreeNode node) {
Stack stack = new Stack();
TreeNode current = node;
while (current != null || !stack.isEmpty()) {
while (current != null) {
stack.push(current);
current = current.left;
}
TreeNode lastNode = stack.pop();
System.out.print(lastNode.value + " ");
current = lastNode.right;
}
}
Output: 3 2 4 5 1 6 7
Code analysis:
Notice that the code above has a similar idea to the recursive algorithm. First, we populate the stack with the left nodes. Then, we print the latest node from the left and search for the right node. If the right node is null, then the previously inserted elements from the stack will be popped out and printed.
Remember that in the in-order traversal, the left leaf nodes must be printed first. That’s why the elements from the left are stacked up first too.
Big (O) Notation for Depth First Search
The Big (O) notation is very important to know as a programmer. That’s because it’s possible to roughly know what is the performance and how much space an algorithm uses.
Time Complexity = O(Vertices+Edges) Space Complexity = O(N) – Recursive methods count as space because those methods will be temporarily in the memory heap using memory. The recursive methods are stacked up and will be removed from the stack whenever they are fully executed. Therefore, it’s not the same as the time complexity.
Summary
The depth-first-search algorithm will visit the depth nodes first and then the nodes closer to the root. As we’ve seen we can use this algorithm for graphs or tree data structures.
We can use the preorder, postorder, and in-order, algorithms to traverse graphs. Notice also that it’s much easier to use the depth-first-search algorithms with a binary tree instead of a graph that might be cyclic or have more than two children nodes. Therefore, let’s recap the main points:
- The depth-first search algorithm is useful to traverse nodes in depth.
- Recursion makes the code much simpler when implementing a depth-first search algorithm
- preorder depth-first search will start from the root, then will traverse to the left and right subtrees
- post-order depth-first search will start from the left subtree, then the right subtree, and finally the root
- in-order depth-first search will start from the left subtree, the root, and finally the right subtree
- It’s easier to implement the depth-first search algorithm with a binary tree instead of a cyclic graph
- A graph can be cyclic, but a tree can not be cyclic





