Since the beginning of my career, I had to deal with databases by inserting, updating, searching, and deleting. Databases concepts are crucial for every developer to understand because they are present in nearly all applications.
Nowadays, with Microservices, this knowledge is even more important. That’s because every Microservice may have different needs, and using the right database makes all the difference.
Let’s see the components of a database so it’s easier for you to learn new databases and do well in a systems design interview.
Computer Storage
Computer storage is the digital space where data is saved and stored in a computer system. It allows you to keep and access data even after you turn off your computer.
There are two main types of computer storage:
Primary storage: It is also known as memory and includes Random Access Memory (RAM) and Cache. The computer uses RAM to store data that is currently being used, while Cache is used to store frequently accessed data to speed up processing.
Secondary storage includes hard disk drives (HDDs), solid-state drives (SSDs), and external drives. These storage devices can store large amounts of data, ranging from documents to music and videos, and can be accessed anytime.
Storage capacity is usually measured in bytes, kilobytes (KB), megabytes (MB), gigabytes (GB), terabytes (TB), and petabytes (PB). The higher the storage capacity, the more data a computer can store.
It’s important to regularly back up your data to prevent loss in case of a computer failure or other incidents. Cloud storage is becoming increasingly popular as a secure and convenient way to store data remotely.
Data in Disk
Most databases will insert data in a disk, meaning the data will be persisted, and even if there is an outage, the data can be retrieved. Let’s see some of the databases that are persistent on the disk.
Databases such as Postgres, Oracle, MySQL, and SQL Server, MongoDB store data on disk
Data in Memory
Databases that make use of cache are databases that store data in memory. They are also called In-memory databases (IMDBs). Some examples of in-memory databases are Redis, Hazelcast, Ehcache, ArangoDB, H2, Memcached, and Apache Ignite.
Those databases will significantly enhance performance when the same data must be retrieved many times. The drawback is that the data will be lost if there is an outage.
Databases
A database collects organized data stored and managed in a computer system. It is designed to efficiently store, retrieve, and manage large amounts of data and can be used by various applications and users.
In a database, data is typically organized into tables of rows and columns. Each row represents a unique record, while each column represents a specific attribute or information about the record. The data is stored in a structured way, which makes it easy to search, sort, and analyze.
Databases are used in various applications, including business, education, research, healthcare, and more. They are essential for managing and organizing large amounts of data and support many important functions, such as customer relationship management, inventory management, financial reporting, etc.
RDBMS (Relational Database Management System)
Relational databases such as Postgres, MySQL, and Oracle will have the data organized in tables that relate to each other using constraints. Those databases are highly reliable for consistency, meaning that you will always get the latest data, and it’s also possible to have high availability since those databases can be replicated in different nodes (cloud machines).
ACID Transactions
ACID is a set of properties that ensure reliable and consistent database transactions.
Atomicity: Transactions are treated as a single unit of work. Either all the changes in a transaction are applied, or none of them are. There are no partial or incomplete transactions. This is very important for financial transactions. Suppose you need to withdraw money. Then the system checks if money is available and will give you the money. You won’t lose the money if any problem occurs during this transaction.
Consistency: Transactions bring the database from one valid state to another. The data in the database follow predefined rules or constraints, ensuring it is always valid. An example is the foreign key, which ensures a register will be inserted in two tables about the primary key from another table. Therefore, the consistency principle won’t allow this process if we try to delete the register with the primary key.
Isolation: Transactions are executed independently and do not interfere with each other. Even if multiple transactions happen simultaneously, each transaction is isolated and will be executed in order.
Durability: Once a transaction is successfully committed, its changes are permanent and will survive future failures or system crashes. In other words, the data will persist in the disk and be available even if an outage happens.
In simple terms, ACID ensures that transactions are treated as a whole, maintain data integrity, work independently, and are resilient to failures. These properties are important for reliable and consistent database operations.
NoSQL
NoSQL stands for Not Only SQL, and nowadays, there are many famous of them. The great advantage of most NoSQL databases is that performance and amount of data are higher than relational databases. On the other hand, it’s not as good to have sophisticated table relationships or be as consistent as a relational database.
Here are some key principles and features of NoSQL databases:
Schemaless: NoSQL databases are schemaless, meaning we can’t have a structure for tables. This flexibility allows dynamic and evolving data structures without migrations or schema alterations.
Scalability and Performance: NoSQL databases handle massive data and high read/write workloads. They provide horizontal scalability by allowing data to be distributed out-of-the-box across multiple servers or clusters, enabling efficient scaling as data volumes and user traffic increase.
High Availability: NoSQL databases often replicate data across multiple nodes, ensuring that if one node fails, the data remains accessible from other nodes. This replication provides high availability and fault tolerance in distributed environments.
Data Models: NoSQL databases offer various data models, including key-value stores, document stores, column-family stores, and graph databases. Each data model caters to different use cases and provides additional capabilities for organizing and retrieving data.
Key-Value Stores: These databases store data as a collection of key-value pairs, allowing fast lookups and writes. Examples include Redis and Amazon DynamoDB.
Document Stores: Document databases store semi-structured or unstructured data as documents, typically in JSON or XML format. They provide flexibility in data representation and retrieval. Examples include MongoDB and Couchbase.
Column-Family Stores: Columnar databases store data in columns rather than rows, making them efficient for handling large amounts of structured data. Examples include Apache Cassandra and HBase.
Graph Databases: Graph databases focus on modeling and querying relationships between data entities. They are suitable for use cases involving complex relationships and network analysis. Examples include Neo4j and Amazon Neptune.
Use Cases: NoSQL databases find frequent use in scenarios that demand high scalability, real-time data processing, and the management of large volumes of unstructured or semi-structured data. They commonly feature in web applications, real-time analytics, content management systems, and Internet of Things (IoT) applications.
Remember that NoSQL databases do not eliminate the need for relational databases. Relational databases are still well-suited for applications that require complex transactions, strong consistency, and pre-defined structured data. NoSQL databases provide an alternative approach that prioritizes scalability, flexibility, and performance in large-scale distributed systems.
CAP Theorem
With the advancement in cloud technologies, now it’s possible to use a database in multiple machines (also called nodes). This means that it’s possible to have massive scaling with data nowadays. There is even a term for that which is big data.
With relational databases, it’s only possible to scale vertically, making one machine where the database is running more powerful and performant. This is expensive, though.
Using NoSQL databases and cloud technologies makes it possible to scale vertically, which is cheaper. Data will be synchronized between all machines, and data will be processed in parallel. With modern cloud technologies, this is possible to accomplish.
The CAP theorem is a graphic that demonstrates what we want to prioritize for your database. We can choose two of the characteristics between consistency, availability, and partition tolerance.
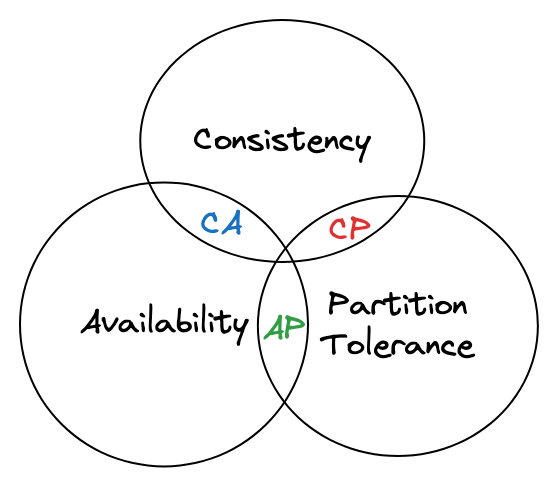
Let’s explore the explanation from each of the database characteristics.
Consistency means that the data will be the data we want to retrieve, not stale. When we have a database replicated in many nodes (cloud machines), there are many processes in parallel to make the data consistent and reliable to what was inserted in the database. Therefore, if your use case requires you to always return the latest data in the database, you must prioritize consistency. Consistency is required for bank operations. For example, the data must be the latest always; otherwise, money can be lost.
Availability means that your database must be up and running no matter if other nodes are down. Your databases must have a mechanism to create other nodes if a node is down. Your database must also have a replication strategy to reflect data in other nodes. If high availability is a must-have for you, you must think of a strategy to replicate nodes even in different countries so that if the servers from a country go down, you will have a backup server to run and replicate your database.
Partition Tolerance: Partition tolerance refers to the ability of a distributed system to continue functioning and providing consistent and available services despite network partitions or communication failures between nodes. Network partitions occur when nodes in a distributed system are separated and cannot communicate with each other because of an outage or network issues. Partition tolerance is crucial for systems that span multiple data centers or rely on unreliable network connections.
Now let’s see the possible CAP theorem combination of characteristics and which databases use them:
CA (Consistency and Availability: Postgres, MySQL, Vertica, and Spanner are examples of databases that focus on consistency and availability. This means we will always have up-to-date data for those databases in one or multiple nodes. MySQL and Postgres can also replicate data in multiple nodes, therefore, being more available if one of the nodes goes down. It also guarantees the latest data even when using multiple nodes.
CP (Consistency and Partition Tolerance): MongoDB, Redis, MemcacheDB, and HBase are good examples of databases with consistency and partition tolerance. Data consistency is the top priority in a CP (Consistency and Partition tolerance) system, even in network partitions. Consistency ensures that all nodes have the same data at the same time. However, prioritizing consistency may lead to temporary unavailability during network partitions. CP systems, such as financial systems, are used in applications where data consistency is critical. The trade-off between consistency and availability varies, and different distributed systems offer different consistency and availability guarantees.
AP (Availability and Partition Tolerance): Apache Cassandra, Amazon DynamoDB, CouchDB, and Apache HBase are databases that use AP. AP systems prioritize high availability and the ability to function despite network partitions. In these systems, maintaining data consistency takes a backseat to ensure system uptime and responsiveness. They allow temporary inconsistencies in data and focus on eventual consistency, which means that data will be synchronized between nodes after some time or conflict resolution mechanisms. AP systems, such as distributed caching and real-time collaborative applications, are essential when availability and fault tolerance are available. While they may still provide some level of consistency, it is typically weaker or eventual rather than strong consistency.
When to use Relational Database in a Systems Design Interview?
The relational database is very effective when organizing complex data and having a relation between tables. Let’s see some of the key points on when we should use a relational database:
- Structured data: when the data needs to be pre-defined in multiple table relationships with constraints.
- Medium Volume: when there is no necessity to store massive data
- ACID: When we need consistency, robustness, and reliability in the stored data
Reasons to avoid Relation Database:
- It doesn’t scale horizontally as well as NoSQL. This means that we have to optimize only one server where the database is running to scale the database to have vertical scaling.
- It’s not effective to store massive data.
- There is no flexibility in inserting data.
When to Use NoSQL Database in a Systems Design Interview?
NoSQL is effective when we need to insert massive data. It’s flexible to store structured or unstructured data and scalable and fast.
- Unstructured data: even though NoSQL is flexible to be used with structured and unstructured data, it doesn’t have the same power to structure data as relational databases. It’s quite slow to perform complex queries. We must accept that we will store and retrieve data from one table with NoSQL.
- Flexibility: since the data from NoSQL is unstructured, there is the flexibility to insert whatever data we want in a table. This might be useful if the data is random.
- Large data volume: when it’s necessary to store massive data in the database, NoSQL is a good choice.
- Scales Horizontally: In the cloud era, this is very important since it’s possible to have multiple nodes of the NoSQL database in different machines from a cluster. This means that NoSQL is highly scalable.
- Cheaper: Since horizontal scaling is cheaper than vertical scaling, NoSQL has an advantage over relational databases.
Reasons to avoid NoSQL:
- It doesn’t support ACID.
- It’s not good for complex relational database models since queries will be very slow.
- There will be a learning curve since there is no standard with NoSQL, depending on the technology you choose.
Conclusion
When deciding what database technology to use, understanding what comes before it is useful. In a Systems design interview, we will have to understand fundamentals so it’s faster to learn a technology. You have to know if you want your database to store information on disk for persistence or in memory for performance. Nowadays, there are so many technologies that knowing the fundamentals saves us a lot of time because we won’t need to learn them in depth because they implement the fundamentals.