

We use the concept of leader election more often than we think with MicroServices and Systems Design. In the Systems Design interview, it’s also a crucial concept to know because that will make a difference when designing a highly scalable system.
The good news is that we don’t need to know the behind-the-scenes algorithms or the ins and outs of leader election. We need to know instead when to apply this concept to build scalable MicroServices.
By knowing this fundamental, it will be much easier to master technologies and tools that implement this concept. Mastering fundamentals is the biggest hack to learn anything faster as a software engineer. Being curious is also very powerful to be a fantastic software engineer.
What is Leader Election?
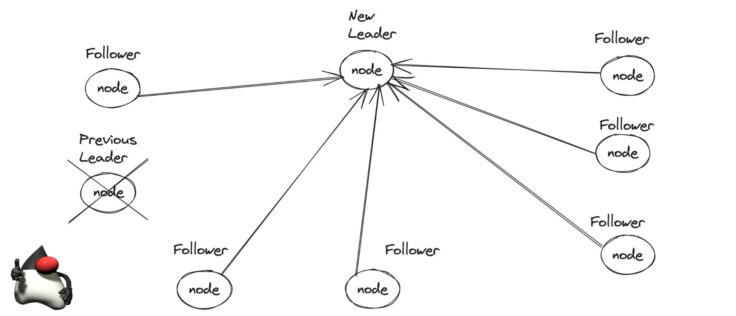
Leader election is a process in distributed systems where a group of nodes or processes choose a single leader to coordinate their actions. The leader is responsible for making decisions and managing the overall behavior of the group.
The purpose of leader election is to ensure that there is a designated leader at all times, even in the presence of failures or changes in the system. Having a leader helps achieve coordination, efficient communication, and consistency among the nodes.
Here’s a simple explanation of how leader election works:
Initial State: In the beginning, all the nodes in the system are equal, and there is no designated leader.
Election Process: When a node detects no leader or the current leader has failed, it initiates the election process. The node sends a message or a signal to all other nodes indicating its desire to become the leader.
Election Messages: Upon receiving an election message, a node compares the priority or identifier of the sender with its own. The node with the highest priority becomes a candidate for the leader position.
Acknowledgment: If a node receives an election message from a node with a higher priority than itself, it acknowledges the message and withdraws its candidacy. This process ensures that only the node with the highest priority continues in the election.
Election Result: Eventually, only one node will remain as the candidate with the highest priority. This node declares itself the leader and broadcasts a victory message to all other nodes.
Leader Acknowledgment: Upon receiving the victory message, all other nodes recognize the new leader and acknowledge its leadership.
Coordination: Once the leader is elected and acknowledged, it assumes the responsibility of coordinating the actions of the nodes in the system. It may initiate further communication, assign tasks, or make decisions on behalf of the group.
It’s important to note that leader election algorithms can vary depending on the specific requirements and characteristics of the distributed system. Various approaches and protocols, such as the Bully Algorithm, Ring Algorithm, or Paxos, can be used to implement leader election in different scenarios.
Challenges of Leader Election
Leader election in distributed systems can pose several challenges. Here are some common challenges that may arise during the leader election process:
Network Communication: Leader election relies on the nodes communicating with each other to exchange messages and determine the leader. However, the network connections between nodes may be unreliable, resulting in message delays, packet loss, or network partitions. These communication issues can lead to inconsistencies and difficulties in reaching a consensus on the leader.
Node Failures: In a distributed system, nodes can fail due to hardware or software issues. When a node fails during the leader election process, it can disrupt the process and potentially lead to an incorrect or inconsistent leader selection. Handling node failures and ensuring fault tolerance is a critical challenge in leader election.
Concurrent Elections: In some cases, multiple nodes may initiate leader election simultaneously due to network delays or failures. Concurrent elections can cause conflicts and result in the selection of multiple leaders, leading to inconsistent behavior and coordination issues within the system. Coordinating and resolving concurrent elections is challenging to ensure a single, stable leader.
Scalability: As the number of nodes in a distributed system increases, the complexity of leader election also grows. Scalability becomes a challenge as the overhead of communication and coordination increases with a larger number of nodes. Leader election algorithms need to be designed to handle the scalability requirements of the system.
Timing and Synchronization: Leader election algorithms often rely on timing and synchronization assumptions. However, in distributed systems, nodes may have different clocks or experience clock drift, making it challenging to establish a common notion of time. Ensuring accurate timing and synchronization among nodes is crucial to avoid inconsistencies and conflicts in leader elections.
Byzantine Failures: In some cases, nodes in a distributed system may exhibit malicious or faulty behavior, known as Byzantine failures. These nodes can intentionally send incorrect or misleading messages during the leader election process, leading to incorrect leader selection or system disruption. Protecting against Byzantine failures is a challenge in ensuring the integrity and correctness of leader elections.
Addressing these challenges requires careful design and implementation of leader election algorithms, considering network conditions, fault tolerance, concurrency, scalability, and security factors. Various distributed consensus protocols, such as Paxos or Raft, have been developed to tackle these challenges and provide reliable leader election mechanisms in distributed systems.
Technologies for Leader Election
Several technologies and algorithms are available for implementing leader election in distributed systems. Here are some commonly used ones:
ZooKeeper: ZooKeeper is a popular open-source distributed coordination service that provides primitives for implementing leader election. It offers a high-performance and reliable platform for managing distributed systems. ZooKeeper uses the ZAB (ZooKeeper Atomic Broadcast) protocol, which ensures consistency and fault tolerance in leader elections.
Apache Kafka: Apache Kafka is a distributed streaming platform that we can use for leader election scenarios. Kafka uses a distributed consensus protocol called Apache Kafka’s Controller Election Protocol (KCEP) to elect a leader among the Kafka brokers. The elected leader manages metadata and coordinates the activities of the Kafka cluster.
etcd: etcd is a distributed key-value store that we can often use as a coordination service in distributed systems. It provides a simple API for storing and retrieving data in a distributed manner. We can leverage etcd for leader election by utilizing its watch feature to monitor changes in a specific key representing the leader position.
Apache Mesos: Apache Mesos is a distributed systems kernel that enables the efficient sharing of resources across clusters. Mesos includes a built-in leader election mechanism called the Master-Slave architecture. In this architecture, multiple Mesos masters compete to be the leader, and the elected leader manages resource allocation and scheduling decisions for the Mesos cluster.
Consul: Consul is a service mesh and service discovery tool that also offers leader election capabilities. It uses the Raft consensus algorithm to elect a leader among a cluster of nodes. The elected leader can then manage coordination and synchronization tasks within the system.
Raft: Raft is a consensus algorithm that can be used for leader election in distributed systems. It ensures strong consistency and fault tolerance in the presence of failures. Raft divides the nodes into three roles: leader, follower, and candidate. Through a series of message exchanges and voting, a leader is elected among the candidates.
Paxos: Paxos is another consensus algorithm commonly used for leader election. It provides a fault-tolerant approach to ensure consistency and agreement among distributed nodes. Paxos elects a leader through a series of message exchanges and voting rounds, and the elected leader coordinates the actions of the nodes.
These technologies and algorithms provide different features, trade-offs, and capabilities for leader election in distributed systems. The choice of technology depends on the specific requirements, scale, and characteristics of the system being built.
Summary
Now that we explored the key points from the leader election concept let’s recap:
- Leader election is a process used in distributed systems to select a single node as the leader or coordinator. It ensures that there is a designated leader responsible for making decisions and coordinating actions within the distributed system.
- Leader election algorithms are designed to handle scenarios where the current leader fails, becomes unavailable, or needs to be replaced.
- Various leader election algorithms exist, such as the Bully algorithm, the Ring algorithm, the Paxos algorithm, and the Raft algorithm.
- Leader election algorithms typically involve a set of nodes communicating and exchanging messages to determine the most suitable candidate for the leader position.
- Nodes may use criteria such as their priority, availability, or a unique identifier to establish the leader.
- The leader is responsible for tasks like resource allocation, task distribution, and consistency maintenance in the distributed system.
- Leader election is crucial for maintaining the system’s resilience, fault tolerance, and overall stability.
- Once a leader is elected, it typically remains in power until it fails, loses connectivity, or a new leader election is triggered due to specific conditions.
- Leader election algorithms often incorporate mechanisms to handle scenarios like network partitions, where the distributed system may split into multiple groups with different leaders.






Do you have an example on how to implement using RDBMS?