Mastering the fundamentals of cache for Systems Design interviews is crucial since this knowledge will be required very often. The cache will significantly increase performance when designing your systems, even more nowadays when systems are in the cloud. Also, the cache makes an even more significant difference when there are many users. If more than 1 million users access part of the system, the cache will make a massive difference in performance.
Let’s then explore the most important cache concepts, in what situations we should use them, and the technologies that implement them.
Eviction Cache Policies
Eviction cache policies determine which items are evicted or removed from the cache when it reach its capacity limit. Here are some commonly used eviction cache policies:
LRU (Least Recently Used)
LRU (Least Recently Used) is a caching algorithm that determines which items or data elements should be evicted from a cache when it reaches capacity. The idea behind LRU is to prioritize removing the least recently accessed items from the cache, keeping the most recently accessed items in the cache because they are more likely to be reaccessed.
LRU General Use Cases
We widely use the LRU (Least Recently Used) caching algorithm in various applications and scenarios where efficient caching of frequently accessed data is crucial. Here are some everyday use cases for LRU caching:
Web Caching: LRU is commonly employed to store frequently accessed web pages, images, or other resources in memory. Keeping the most recently accessed content in the cache reduces the load on backend servers and improves response times for subsequent requests.
Database Query Result Caching: In database systems, we can use LRU caching to cache the results of frequently executed database queries. LRU helps avoid repeated database access and speeds up query response times.
File System Caching: File systems often utilize LRU caching to cache frequently accessed files or file blocks. LRU reduces disk I/O operations and improves overall file system performance.
CPU Cache Management: CPUs employ LRU-based cache replacement policies to manage the cache hierarchy effectively. The CPU cache can minimize cache misses and improve overall processor performance by prioritizing the most recently accessed data.
Network Packet Caching: We can use LRU caching to cache frequently accessed network packets or data chunks in networking applications. LRU can enhance network performance by reducing the need for repeated data transmission.
API Response Caching: APIs that serve frequently requested data can benefit from LRU caching. By storing and doing the most recently accessed API responses, the caching layer can reduce the load on backend systems and improve the API’s response time.
Compiler Optimization: During the compilation process, compilers often employ LRU caching to store frequently used intermediate representations or symbol tables. LRU can speed up subsequent compilation stages and improve overall compilation time.
These are just a few examples of using LRU caching in various domains and applications. The primary goal is to reduce latency, improve response times, and optimize resource utilization by keeping frequently accessed data readily available in a cache.
LRU Real-World Use Cases
Let’s see some use cases where we could use LRU from famous systems we use daily.
Youtube
Let’s explore potential use cases where we can use LRU (Least Recently Used) caching algorithms on YouTube:
Video Thumbnail Caching: YouTube could utilize LRU caching to store and serve frequently accessed video thumbnails. Thumbnails are often displayed in search results, recommended videos, and video player previews. Caching the most recently accessed thumbnails can significantly reduce the backend systems load and improve thumbnail retrieval responsiveness.
Recommended Videos: YouTube’s recommendation system could utilize LRU caching to store and serve recommended videos based on a user’s viewing history and preferences. Caching recommended videos can improve recommendation response times and reduce the computational load on the recommendation engine.
User Profile Caching: Instagram could cache frequently accessed user profiles to improve the response times when displaying profile information, posts, followers, and other profile-related data. Caching user profiles allows for faster retrieval and reduces the load on backend systems, enhancing the user experience.
User Stories: Instagram may cache user stories, including images, videos, stickers, and interactive elements. Caching stories helps ensure smooth playback and reduces the load on the backend systems when displaying stories to users.
Netflix
Let’s explore some potential use cases where LRU (Least Recently Used) caching algorithms could be applied on Netflix:
Movie and TV Show Metadata: Netflix could cache frequently accessed movie and TV show metadata, including titles, descriptions, genres, cast information, and ratings. Caching this information improves the responsiveness of search results, recommendation algorithms, and content browsing, reducing the need for repeated database queries.
Video Playback Data: Netflix may cache video playback data, such as user progress, watch history, and subtitle preferences. Caching this data allows users to resume watching a video from where they left off and maintain their preferred settings without requiring frequent backend server communication.
Least Frequently Used (LFU)
LFU (Least Frequently Used) is an eviction cache policy that aims to remove the items accessed the least number of times from the cache. It assumes that items frequently accessed are more likely to be accessed in the future.
Here’s how LFU eviction works:
Tracking Access Frequency: LFU maintains a frequency count for each item in the cache. An item’s access frequency count is incremented whenever accessed or requested.
Eviction Decision: When the cache reaches its capacity limit and a new item needs to be inserted, LFU examines the access frequency counts of the items in the cache. It identifies the item with the least access frequency or the lowest count.
Eviction of Least Frequently Used Item: The item with the lowest access frequency count is evicted from the cache to make room for the new item. If multiple items have the same lowest count, LFU may use additional criteria, such as the time of insertion, to break ties and choose the item to evict.
Updating Access Frequency: After the eviction, LFU updates the access frequency count of the newly inserted item to indicate that it has been accessed once.
LFU is based on the assumption that items that have been accessed frequently are likely to be popular and will continue to be accessed frequently in the future. By evicting the least frequently used items, LFU aims to prioritize keeping the more frequently accessed items in the cache, thus maximizing cache hit rates and improving overall performance.
However, LFU may not be suitable for all scenarios. It can result in the eviction of items that were accessed heavily in the past but are no longer relevant. Additionally, LFU may not handle sudden changes in access patterns effectively. For example, if an item was rarely accessed in the past but suddenly becomes popular, LFU may not quickly adapt to the new access frequency and may prematurely evict the item.
Therefore, it’s important to consider the specific characteristics of the workload and the behavior of the cached data when choosing an eviction cache policy like LFU.
LFU General Use Cases
Here are some potential use cases where the LFU (Least Frequently Used) eviction cache policy can be beneficial:
Web Content Caching: LFU can be used to cache web content such as HTML pages, images, and scripts. Frequently accessed content, which is likely to be requested again, will remain in the cache, while less popular or rarely accessed content will be evicted. This can improve the responsiveness of web applications and reduce the load on backend servers.
Database Query Result Caching: In database systems, LFU can be applied to cache the results of frequently executed queries. The cache can store query results, and LFU ensures that the most frequently requested query results remain in the cache. This can significantly speed up subsequent identical or similar queries, reducing the need for repeated database accesses.
API Response Caching: LFU can be used to cache responses from external APIs. Popular API responses that are frequently requested by clients can be cached using LFU, improving the performance and reducing the dependency on external API services. This is particularly useful when the API responses are relatively static or have limited change frequency.
Content Delivery Networks (CDNs): LFU can be employed in CDNs to cache frequently accessed content, such as images, videos, and static files. Content that is heavily requested by users will be retained in the cache, resulting in faster content delivery and reduced latency for subsequent requests.
Recommendation Systems: LFU can be utilized in recommendation systems to cache user preferences, item ratings, or collaborative filtering results. By caching these data, LFU ensures that the most relevant and frequently used information for generating recommendations is readily available, leading to faster and more accurate recommendations.
File System Caching: LFU can be applied to cache frequently accessed files or directory structures in file systems. This can improve file access performance, especially when certain files or directories are accessed more frequently than others.
Session Data Caching: In web applications, LFU can cache session data, such as user session variables or session-specific information. Frequently accessed session data will be kept in the cache, reducing the need for repeated retrieval and improving application responsiveness.
It’s important to note that the suitability of LFU for a specific use case depends on factors such as access patterns, data popularity, and cache capacity. Each system should evaluate its requirements and consider the pros and cons of different eviction cache policies to determine the most appropriate approach.
Real Use Cases from LFU
Let’s see some use cases where we could use LFU from famous systems we use daily.
Youtube
YouTube could use LFU caching for storing and serving frequently accessed video metadata, such as titles, descriptions, thumbnails, view counts, and durations. The LFU cache would prioritize caching the metadata of popular and frequently viewed videos, as users are more likely to watch them.
User Feed and Explore Recommendations: Instagram could utilize LFU caching for storing and serving user feeds and exploring recommendations. The user feed displays posts from accounts that users follow, while the explore section suggests content based on the user’s interests and browsing history.
Netflix
- Netflix could utilize LFU caching for storing and serving frequently accessed movie or TV show metadata, such as titles, descriptions, genres, and cast information.
- The LFU cache would prioritize caching the metadata of popular and frequently watched content, as they are more likely to be requested by users.
Write Through Cache
A write-through cache is a caching technique that ensures data consistency between the cache and the underlying storage or memory. In a write-through cache, whenever data is modified or updated, the changes are simultaneously written to both the cache and the main storage. This approach guarantees that the cache and the persistent storage always have consistent data.
Here’s how the write-through cache works:
Data Modification: When a write operation is performed on the cache, the modified data is first written to the cache.
Write to Main Storage: After the data is written to the cache, it is immediately propagated or “written through” to the main storage or memory. This ensures that the updated data is permanently stored and persisted.
Data Consistency: By writing through to the main storage, the write-through cache ensures that the cache and the underlying storage always have consistent data. Any subsequent read operation for the same data will retrieve the most up-to-date version.
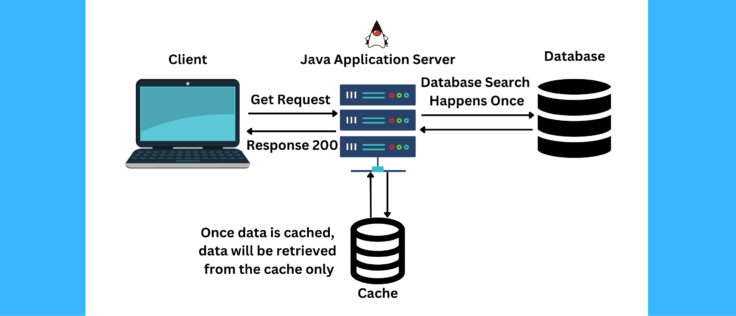
Read Operations: Read operations can be serviced by either the cache or the main storage, depending on whether the requested data is currently present in the cache. If the data is in the cache (cache hit), it is retrieved quickly. If the data is not in the cache (cache miss), it is fetched from the main storage and then stored in the cache for future access.
Advantages of Write-Through Cache
Data Consistency: The write-through cache maintains data consistency between the cache and the main storage, ensuring that modifications are immediately reflected in the persistent storage.
Crash Safety: Since data is written to the main storage simultaneously, even if there is a system crash or power failure, the data remains safe and up-to-date in the persistent storage.
Read Performance: Read operations can benefit from the cache, as frequently accessed data is available in the faster cache memory, reducing the need to access the slower main storage.
Simplicity: Write-through cache implementation is relatively straightforward and easier to manage than other caching strategies.
Disadvantages of Write-Through Cache
Write Latency: The write operation in the write-through cache takes longer as it involves writing to both the cache and the main storage, which can increase the overall latency of write operations.
Increased Traffic: The write-through cache generates more write traffic on the storage subsystem, as every write operation involves updating both the cache and the main storage.
Limited Write Performance Improvement: Write-through caching doesn’t significantly enhance write performance, as the speed of the main storage still limits the writes.
Write-through caching is commonly used in scenarios where data consistency is critical, such as in databases and file systems, where immediate persistence of updated data is essential.
Time-To-Live (TTL): This policy associates a time limit with each item in the cache. When an item exceeds its predefined time limit (time-to-live), it is evicted from the cache. TTL-based eviction ensures that cached data remains fresh and up-to-date.
Random Replacement (RR): This policy randomly selects items for eviction from the cache. When the cache is full, and a new item needs to be inserted, a random item is chosen and evicted. Random replacement does not consider access patterns or frequencies and can lead to unpredictable cache performance.
Memoization
Memoization is a technique used in computer programming to optimize the execution time of functions by caching the results of expensive function calls and reusing them when the same inputs occur again. It is a form of dynamic programming that aims to eliminate redundant computations by storing the results of function calls in memory.
Storing data in a Map is a good example. In the recursive Fibonacci algorithm, we can use a Map to store (cache) repeated Fibonacci numbers to avoid processing a number already computed.
FIFO Cache
FIFO (First In, First Out) cache is a cache eviction policy that removes the oldest inserted item from the cache when it reaches its capacity limit. In other words, the item in the cache for the longest duration is the first to be evicted when space is needed for a new item. Remember, in a real-world queue, if you are the first person in the queue, you will be attended first.
Here’s how FIFO cache eviction works:
Insertion of Items: When a new item is inserted into the cache, it is placed at the end of the cache structure, becoming the most recently added item.
Cache Capacity Limit: As the cache reaches its capacity limit and a new item needs to be inserted, the cache checks if it is already full. If it is full, the FIFO policy comes into play.
Eviction Decision: In FIFO, the item that has been in the cache the longest (i.e., the oldest item) is selected for eviction. This item is typically the one at the front or beginning of the cache structure, representing the first item that entered the cache.
Eviction of Oldest Inserted Item: The selected item is evicted from the cache to make room for the new item. Once the eviction occurs, the new item is inserted at the end of the cache, becoming the most recently added item.
FIFO cache eviction ensures that items that have been in the cache for a longer time are more likely to be evicted first. It is a simple and intuitive eviction policy that can be implemented without much complexity.
However, FIFO may not always be the best choice for cache eviction, as it does not consider the popularity or frequency of item accesses. It may result in the eviction of relevant or frequently accessed items that were inserted earlier but are still in demand.
Therefore, it’s essential to consider the specific characteristics of the workload and the access patterns of the cached data when selecting an eviction cache policy like FIFO.
LIFO
LIFO (Last In, First Out) cache is a cache eviction policy that removes the most recently inserted item from the cache when it reaches its capacity limit. In other words, the item that was most recently added to the cache is the first one to be evicted when space is needed for a new item.
Here’s how LIFO cache eviction works:
Insertion of Items: When a new item is inserted into the cache, it is placed at the top of the cache structure, becoming the most recently added item.
Cache Capacity Limit: As the cache reaches its capacity limit and a new item needs to be inserted, the cache checks if it is already full. If it is full, the LIFO policy comes into play.
Eviction Decision: In LIFO, the item that was most recently inserted into the cache is selected for eviction. This item is typically the one at the top of the cache structure, representing the last item that entered the cache.
Eviction of Most Recently Inserted Item: The selected item is evicted from the cache to make room for the new item. Once the eviction occurs, the new item is inserted at the top of the cache, becoming the most recently added item.
LIFO cache eviction is straightforward and easy to implement since it only requires tracking the order of insertions. It is commonly used in situations where the most recent data has a higher likelihood of being accessed or where temporal locality of data is important.
However, LIFO may not always be the best choice for cache eviction, as it can result in the eviction of potentially relevant or popular items that were inserted earlier but are still frequently accessed. It may not effectively handle access pattern changes or skewed data popularity over time.
Therefore, it’s essential to consider the specific characteristics of the workload and the behavior of the cached data when choosing an eviction cache policy like LIFO.
Weighted Random Replacement (WRR)
This policy assigns weights to cache items based on their importance or priority. Low-weight items are more likely to be evicted when the cache is full. WRR allows for more fine-grained control over cache eviction based on item importance.
Size-Based Eviction: This policy evicts items based on size or memory footprint. When the cache reaches its capacity limit, the things that occupy the most space are evicted first. Size-based eviction ensures efficient utilization of cache resources.
What is stale Data?
Stale data refers to data that has become outdated or no longer reflects the current or accurate state of the information it represents. Staleness can occur in various contexts, such as databases, caches, or replicated systems. Here are a few examples:
Caches: In caching systems, stale data refers to cached information that has expired or is no longer valid. Caches are used to store frequently accessed data to improve performance. However, if the underlying data changes while it is cached, the cached data becomes stale. For example, if a web page is cached, but the actual content of the page is updated on the server, the cached version becomes stale until it is refreshed.
Replicated Systems: In distributed systems with data replication, stale data can occur when updates are made to the data on one replica but not propagated to other replicas. As a result, different replicas may have inconsistent or outdated versions of the data.
Databases: Stale data can also occur in databases when queries or reports are based on outdated data. For example, if a report is generated using data from yesterday, but new data has been added since then, the report will contain stale information.
Managing stale data is important to ensure data accuracy and consistency. Techniques such as cache expiration policies, cache invalidation mechanisms, and data synchronization strategies in distributed systems are used to minimize the impact of stale data and maintain data integrity.
Technologies that use Cache
There are several technologies and frameworks that implement caching to improve performance and reduce latency. Here are some commonly used technologies for caching:
Memcached: Memcached is a distributed memory caching system that stores data in memory to accelerate data retrieval. It is often used to cache frequently accessed data in high-traffic websites and applications.
Redis: Redis is an in-memory data structure store that can be used as a database, cache, or message broker. It supports various data structures and provides advanced caching capabilities, including persistence and replication.
Apache Ignite: Apache Ignite is an in-memory computing platform that includes a distributed cache. It allows caching of data across multiple nodes in a cluster, providing high availability and scalability.
Varnish: Varnish is a web application accelerator that acts as a reverse proxy server. It caches web content and serves it directly to clients, reducing the load on backend servers and improving response times.
CDNs (Content Delivery Networks): CDNs are distributed networks of servers located worldwide. They cache static content such as images, videos, and files, delivering them from the nearest server to the user, reducing latency and improving content delivery speed.
Squid: Squid is a widely used caching proxy server that caches frequently accessed web content. It can be deployed as a forward or reverse proxy, caching web pages, images, and other resources to accelerate content delivery.
Java Caching System (JCS): JCS is a Java-based distributed caching system that provides a flexible and configurable caching framework. It supports various cache topologies, including memory caches, disk caches, and distributed caches.
Hazelcast: Hazelcast is an open-source in-memory data grid platform that includes a distributed cache. It allows caching of data across multiple nodes and provides features such as high availability, data partitioning, and event notifications.
These are just a few examples, and there are many other caching technologies available, each with its own features and use cases. The choice of caching technology depends on factors such as the application’s requirements, scalability needs, and the specific use case.
Buffer VS Cache
Buffer and cache are both used in computing and storage systems to improve performance, but they serve different purposes and operate at different levels. Here’s a comparison between buffer and cache:
Buffer:
Purpose: A buffer is a temporary storage area that holds data during the transfer between two devices or processes to mitigate any differences in data transfer speed or data handling capabilities.
Function: Buffers help smooth out the flow of data between different components or stages of a system by temporarily storing data and allowing for asynchronous communication.
Data Access: Data in a buffer is typically accessed in a sequential manner, processed or transferred, and then emptied to make room for new data.
Size: Buffer sizes are usually fixed and limited, and they are often small in comparison to the overall data being processed or transferred.
Examples: Buffers are commonly used in I/O operations, network communication, and multimedia streaming to manage data flow between different components or stages. Youtube and Netflix are good examples of the use of buffering.
Cache:
Purpose: A cache is a higher-level, faster storage layer that stores copies of frequently accessed data to reduce access latency and improve overall system performance.
Function: Caches serve as a transparent intermediary between a slower, larger storage (such as a disk or main memory) and the requesting entity, providing faster access to frequently used data.
Data Access: Caches use various algorithms and policies to determine which data to store and evict, aiming to keep the most frequently accessed data readily available.
Size: Cache sizes are usually larger compared to buffers, and they can vary in size depending on the system’s requirements and available resources.
Examples: Caches are widely used in CPUs (processor cache) to store frequently accessed instructions and data, web browsers (web cache) to store web pages and resources, and storage systems (disk cache) to store frequently accessed disk blocks.
In summary, buffers are temporary storage areas used to manage data transfer or communication between components, while caches are faster storage layers that store frequently accessed data to reduce latency and improve performance. Buffers focus on data flow and synchronization, while caches focus on data access optimization.
Summary
We saw the trade-offs from each cache and when to use them in a real-world situation. Now, let’s see the key points from the cache concept:
- Caching is a technique that stores frequently accessed or computationally expensive data in a faster and more accessible layer.
- It aims to improve performance by reducing the time and resources required to retrieve data. Caching can be applied in various domains, from web applications and databases to content delivery and distributed computing.
- Write-through cache ensures data consistency by simultaneously writing modifications to both the cache and the main storage.
- Memoization is a form of caching that stores the results of expensive function calls and reuses them when the same inputs occur again.
- Caching techniques include write-through cache, write-back cache, LRU cache, FIFO cache, random replacement cache, LFU cache, ARC, Belady’s optimal algorithm, and multi-level caching. Each caching technique has its advantages and trade-offs in terms of performance, eviction policies, and memory usage.
- Caching is used to optimize performance, reduce latency, and improve scalability in data-intensive systems.
- Caching can be particularly effective for repetitive computations, recursive algorithms, and dynamic programming solutions.
- The choice of caching technique depends on factors such as access patterns, resource availability, and specific performance requirements.