


The Hash Table data structure stores keys and values into a variable in Java and other programming languages. It’s also a very common data structure vastly used in day-to-day projects and algorithms.
Let’s see a simple example of how Hash Table information is stored:
key: 1 value: Duke key: 2 value: Juggy key: 3 value: Moby Dock
We can access any of the values by key. Hash Table is a very performant data structure because it can insert, delete, and search by key with the time complexity of O(1) on average. To understand better the term O(1), check out the Big(O) notation article.
A Hash Table is actually built on top of arrays. In Java, for example, the Hashtable class stores an array of key-value Entry:
public class Hashtable
extends Dictionary
implements Map, Cloneable, java.io.Serializable {
/**
* The hash table data.
*/
private transient Entry[] table;
}
Another important detail from the Hash Table data structure is that it has a hash function to make the key unique.
The hash function will transform the data into a specific number that can be easily searchable by key. How the hash function works depends on the type of object. If the key is a String for example, it will transform into UTF-16 encoding by the hashCode implementation.
Notice that the JDK will give us a high-quality hash function meaning that we don’t need to reinvent the wheel by creating other functions. The String, Integer, Double Boolean, and many other classes have their own implementation of hashCode.
The important thing to remember about the hash function is that it has to be performant and has to return an integer code if possible unique per each object.
What is a Hash Function?
Hash functions are used to create almost irreversible cryptographies where the input is almost impossible to retrieve. The most popular one is SHA256. Also, in general, hash functions are mostly used with Password verification, Compiler operations, algorithms such as Robin Carp for pattern searching, and of course, Hash Tables.
In Java, we have the famous method from the Object class called hashCode which is responsible to generate the hash code.
A hash function might be extremely simple, it could be even a constant value but that wouldn’t have any benefit. It could be very simple also, for example, we can create a hash function for an Object to sum the ASCII characters and return an int number:
public class AsciiSumHashFunction {
String anyString;
public AsciiSumHashFunction(String anyString) {
this.anyString = anyString;
}
public static void main(String[] args) {
var asciiSumHash1 = new AsciiSumHashFunction("ABC");
var asciiSumHash2 = new AsciiSumHashFunction("CBA");
System.out.println(asciiSumHash1.hashCode());
System.out.println(asciiSumHash2.hashCode());
}
@Override
public int hashCode() {
int hashCode = 0;
for (int i = 0; i < anyString.length(); i++) {
hashCode += anyString.getBytes()[i];
}
return hashCode;
}
}
Output: 198 198
In this simple example, we get a collision of the hash function even though the data is different. Since A is 65, B is 66 and C is 67 in the ASCII table we will have a result of 198.
Therefore, “ABC” and “CBA” will have the same hash code. Of course, the hash functions in real-world projects are MUCH more effective and complex than that and the chances to have a collision are extremely small. But, still, we can implement a hash function as simple as that or even return a constant value.
Hash function Collision
The probability of a hash collision happening is extremely low, it’s so insignificant that it might not happen at all. That’s because the hash functions we have nowadays are very sophisticated.
However, still there is a very small chance to happen a hash collision, and when that happens, the time complexity to insert, and delete by key, and search elements by the key will be O(n). That is the case because if there is a hash collision, the Hash Table has mechanisms to get around this and it will create a LinkedList (list of chained objects or list of nodes) under a bucket which is called the Separate chaining.
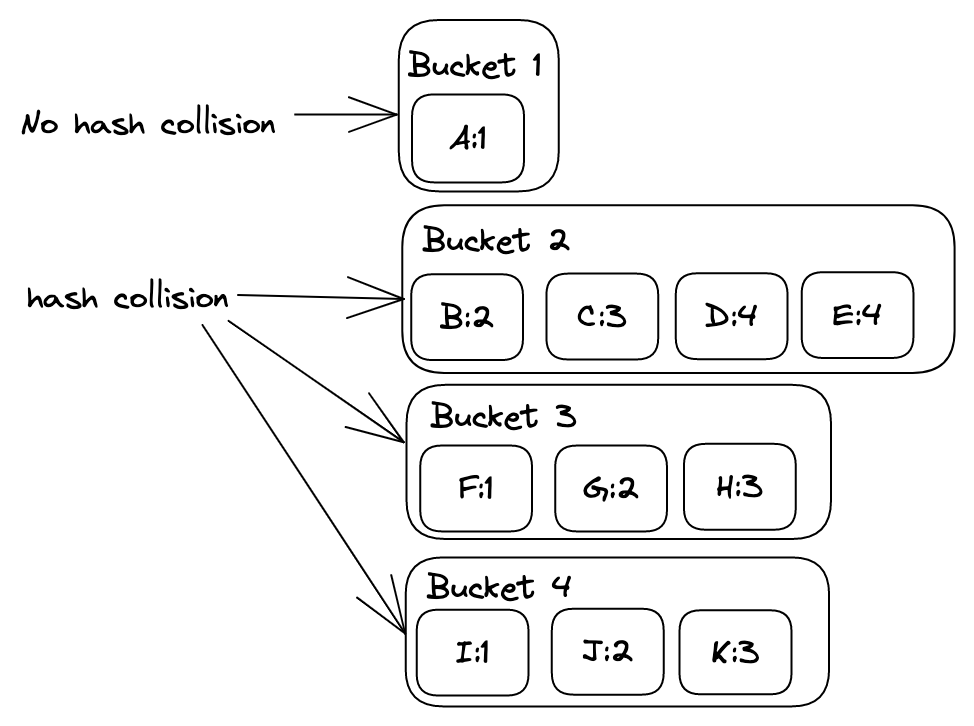
As you can see in the diagram above, in case there is a hash code collision the key value elements will be added to the same bucket. When that happens, they will be LinkedLists (list of nodes), and the only way to find an element will be by checking their full equality of them.
Therefore, instead of having direct access by hashCode in the array, we will have to traverse through each object within the LinkedList until the right element is found. That’s why the time complexity is O(n) when there is a hash collision.
Let’s see this happening in practice in the next section.
Hash collision in practice with Java
Now let’s see what are the consequences of a hash collision. Seeing the hash collision happening but not seeing what this causes won’t help much. That’s the reason I created a comparison where you will see clearly why we should avoid a hash collision and try to optimize the hash code function to be different on each object.
In the following code example, we will create and declare the CollisionBean which will always return the value of 1 within its hashCode method, therefore, forcing a hash collision. We will also have the NoCollision class that will always have a different hash code.
Then we will test their performance by adding and searching elements within a loop of 10000 elements. Let’s see what is the difference in milliseconds between them:
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
public class HashCollisionInPractice {
public static void main(String[] args) {
collisionTest();
noCollisionTest();
}
private static void collisionTest() {
Map collisionMap = new HashMap();
var startTime = System.currentTimeMillis();
// O(n ^ 2)
for (int i = 0; i < 10000; i++) {
collisionMap.put(new CollisionBean(i), i);
collisionMap.get(i);
}
var endTime = System.currentTimeMillis() - startTime;
System.out.println("O(n ^ 2) with collision: " + endTime);
}
private static void noCollisionTest() {
Map noCollisionMap = new HashMap();
var startTime = System.currentTimeMillis();
// O(n)
for (int i = 0; i < 10000; i++) {
noCollisionMap.put(new NoCollisionBean(i), i);
noCollisionMap.get(i);
}
var endTime = System.currentTimeMillis() - startTime;
System.out.println("O(n) without collision: " + endTime);
}
static class CollisionBean {
private Integer value;
public CollisionBean(Integer value) {
this.value = value;
}
@Override
public boolean equals(Object o) {
CollisionBean that = (CollisionBean) o;
return Objects.equals(value, that.value);
}
@Override
public int hashCode() {
return 1; // Always the same hash code forcing a hash collision
}
}
static class NoCollisionBean {
private Integer value;
public NoCollisionBean(Integer value) {
this.value = value;
}
@Override
public boolean equals(Object o) {
CollisionBean that = (CollisionBean) o;
return Objects.equals(value, that.value);
}
@Override
public int hashCode() {
return value; // Different hash code, no hash collision
}
}
}
Output (The output will slightly vary): O(n ^ 2) with collision: 771 O(n) without collision: 4
As you can see in the code above, the performance difference is enormous! When adding and searching 10000 elements the NoCollisionBean is 192 times faster than the CollisionBean. The more elements we add and search the bigger the difference too.
Another important point is that within the loop we have the time complexity of O(n) but when there is a hash collision, there will be another O(n). When we have a time complexity of O(n) and another one inside the loop, we will have O(n ^ 2).
That’s because to search for an element within a LinkedList, it’s necessary to traverse the whole list of nodes and then retrieve the element.
Optimizing Hash Collision in Java
In Java 9 the JEP (JDK Enhancement Proposal) 180 Handle Frequent HashMap Collisions with Balanced Trees there was an optimization that transforms the LikedList from a hash collision into a balanced tree. This means that the nodes from the LinkedList will be sorted in a way that it’s possible to use the binary search algorithm.
By using the binary search algorithm we reduce the time complexity from O(n) to O(log n) which is MUCH faster. A very important point to make this work is that we need to implement Comparable and override the compareTo method. That’s the only way the objects can be compared and sorted within a balanced tree.
Let’s see this huge time complexity difference in practice. First, we will create the CollisionComparableBean that implements Comparable enabling the JDK to create a balanced tree.
Then, we do the same process as before, we add 10000 elements and then search for each element. Since searching each element with the binary search element is MUCH faster, there will be a huge gain in performance as you will see in the following code even if there is a hash collision:
public class HashCollisionInPractice {
public static void main(String[] args) {
collisionTest();
noCollisionTest();
collisionWithBalancedTreeTest();
}
// Ommitted other methods...
private static void collisionWithBalancedTreeTest() {
Map collisionMap = new HashMap();
var startTime = System.currentTimeMillis();
// O(n)
for (int i = 0; i < 10000; i++) {
collisionMap.put(new CollisionComparableBean(i), i);
// O(log n)
collisionMap.get(i);
}
var endTime = System.currentTimeMillis() - startTime;
System.out.println("O(n) with collision and a balanced tree: " + endTime);
}
static class CollisionComparableBean
implements Comparable{
private Integer value;
public CollisionComparableBean(Integer value) {
this.value = value;
}
@Override
public boolean equals(Object o) {
CollisionComparableBean that = (CollisionComparableBean) o;
return Objects.equals(value, that.value);
}
@Override
public int hashCode() {
return 1; // Always the same hash code forcing a hash collision
}
@Override
public int compareTo(CollisionComparableBean o) {
return this.value.compareTo(o.value);
}
}
}
Output (The output will slightly vary): O(n ^ 2) with collision: 722 O(n) without collision: 6 O(n) with collision and a balanced tree: 30
Note that when there is O(n) and O(log n), there is no need to sum both time complexities. Instead, the bigger time complexity O(n) prevails. Also, notice the huge time complexity difference when we are using a balanced tree and when we are not using it. Using a balanced tree is 24 times faster than not using it.
The other important point to reinforce is that the balanced tree will be only created if we have a way to compare objects. In other words, if we have a Comparable interface implemented.
Summary
The Hash Table is a crucial data structure to understand and it’s present in all programming languages. Therefore, by understanding how Java handles it behind the scenes you will pretty much know how to manipulate the Hash Table, Dictionary, HashMap, or whatever the name from any programming language.
Basically, in essence, a Hash Table is a data structure to store key-value data. It’s fast to retrieve data by key and will have hash collision very rarely if we are using effective hashCode implementations.
Let’s see the key points of the Hash Table data structure:
- It is a data structure to handle key and value.
- To search data it’s pretty fast if there is no hash collision. It’s O(1).
- If there is a hash collision and no balanced tree, the time complexity will be O(n) to search by key.
- If there is a hash collision and balanced tree, the time complexity to search by key is O(log n).
- To enable a balanced tree to be used when there is a hash collision, it’s necessary to implement Comparable.
- To search a value (not the key) into a Hash Table we will have the time complexity of O(n).
- The keys of a Hash Table are an array behind the scenes that can be accessed by a hash code. That’s why we have the time complexity of O(1) when there is no hash collision.
- When there is a hash collision, the key, and value will be inserted in a LinkedList. Then the time complexity to search an element by the key will be O(n).





