


The String data structure in Java and in other programming languages behind the scenes is an array of bytes. Bytes behind the scenes are numbers that can be translated into bits or binary numbers. Those numbers correspond to a character in an encoding standard called ASCII (American Standard Code for Information Exchange) as you can see in the following diagram.
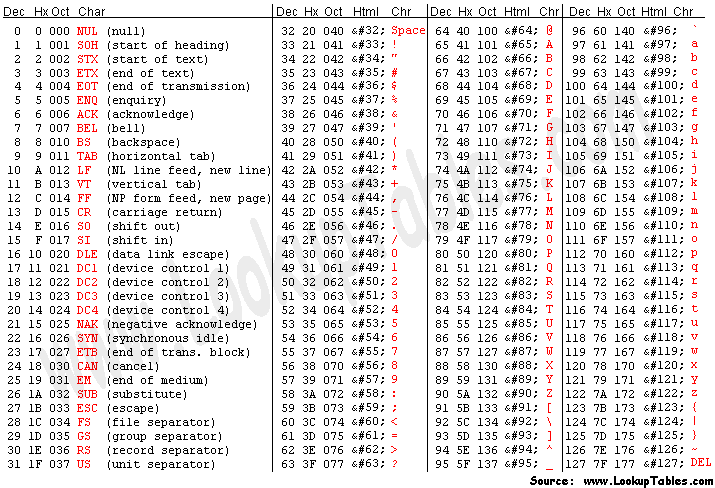
ASCII Codes
Extended ASCII Codes
As you can see in the above diagram, each letter corresponds to a number in the ASCII table. For example, the capital letter “A” is 65, “B” is 66, “C” is 67 and the lowercase letter “a” is 97. It’s important to know that each letter is represented by a number because this concept will surely be used in many algorithms.
The ASCII table has 255 keyboard actions. Between them, there are essential commands for the keyboard, capital and lowercase case characters, special characters, and numbers.
Each ASCII character stores 1 byte in memory which is the same as 8 bits.
Java doesn’t have a primitive type for String. It has actually a class. Also, if you take a look inside the String class, you will notice that actually the String class stores information in an array of bytes:
public final class String
implements java.io.Serializable, Comparable, CharSequence,
Constable, ConstantDesc {
@Stable
private final byte[] value;
// Omitted fields and methods...
}
Characters and ASCII Encoding from a String
Let’s then traverse in a String to show in practice that each String character stores a number from the ASCII table:
public class StringAscii {
public static void main(String[] args) {
String challenger = "ABCDabcd1234";
// O(n) time complexity - O(1) space complexity
for (int i = 0; i < challenger.length(); i++) {
char character = challenger.toCharArray()[i];
byte characterAsciiNumber = challenger.getBytes()[i];
System.out.print(character + ":" + characterAsciiNumber + " ");
}
}
}
Output: A:65 B:66 C:67 D:68 a:97 b:98 c:99 d:100 1:49 2:50 3:51 4:52
Get a character from a String
The time complexity to get a character from a String is O(1). That happens because as mentioned before, a String is actually an array of bytes behind the scenes. You can explore more about arrays in the array data structure article.
If we want to retrieve the first character from a String, we can use the following code:
public class GetCharacterString {
public static void main(String[] args) {
String challenger = "Never Stop Learning";
// O(1) time complexity
System.out.println(challenger.toCharArray()[0]);
}
}
Output: N
Copy a String
In programming languages like C++ a String is mutable. In other programming languages such as Java, Python, C#, Kotlin, and Golang a String is immutable. This means that those Strings will not be changed in memory. Therefore, every time we concatenate a String via code, another String will be created.
This means that whenever we concatenate a String, we will have the time complexity of O(N). That happens because a new array of bytes will be created in memory and then will copy the String array into it.
Let’s see the following code example:
public class CopyStringComplexity {
public static void main(String[] args) {
String duke = "Awesome Duke ";
String juggy = "Awesome Juggy";
String dukeAndJuggy;
// O(n) time complexity
dukeAndJuggy = duke + juggy;
System.out.println(dukeAndJuggy);
}
}
Output: Awesome Duke Awesome Juggy
If we concatenate a String within a loop, then the time complexity will be even worse. We will get the time complexity of O(n^2). Let’s see the following code:
static void concatenateStringOn2Complexity(int n) {
String duke = "Awesome Duke ";
String juggy = "Awesome Juggy";
String dukeAndJuggy = "";
// O(n^2) time complexity
for (int i = 0; i < n; i++) {
dukeAndJuggy = duke + juggy;
}
System.out.println(dukeAndJuggy);
}
Code analysis:
Depending on the n parameter, there will be more concatenations. Also, notice that there is a looping with n and within that loop there will be another loop for n characters the String has to do the concatenation. The above code is very slow. Fortunately, Java provides a class that concatenates a String effectively and significantly reduces the time complexity. Let’s further explore that in the following section.
Effectively Copying String with StringBuilder and StringBuffer
The above code is ineffective to do many String concatenations. When using the StringBuilder class though, the scenario changes. This happens because the StringBuilder class will only create a new array and really concatenate the String.
Let’s see how slow and inefficient normal String concatenation is when we have a great number of concatenations:
public class ConcatenationComparison {
public static void main(String[] args) {
var nSize = 100000;
concatenateString(nSize);
concatenateStringBuilder(nSize);
}
static void concatenateString(int n) {
var timeMillis = System.currentTimeMillis();
String concatString = "";
// O(n2) time complexity
for (int i = 0; i < n; i++) {
concatString += i;
}
var processTime = System.currentTimeMillis() - timeMillis;
System.out.println(processTime + " milliseconds");
}
static void concatenateStringBuilder(int n) {
var timeMillis = System.currentTimeMillis();
StringBuilder concatStringBuilder = new StringBuilder();
// O(n) time complexity
for (int i = 0; i < n; i++) {
concatStringBuilder.append(i);
}
var processTime = System.currentTimeMillis() - timeMillis;
System.out.println(processTime + " milliseconds");
}
}
Output (The output will slightly vary from time to time): 2820 milliseconds 5 milliseconds
As you can see in the code above the difference in time processing is exponential. By using the StringBuilder to concatenate String when doing the looping 100000 times, the StringBuilder will perform 564 times faster than normal concatenation.
That’s why it’s so important to understand what happens behind the scenes with data structures and code, otherwise, we won’t be able to understand why the performance is extremely better with StringBuilder.
Another important class to know about is StringBuffer that has does the same as StringBuilder but is thread-safe, meaning that will avoid data collision when working in a multi-thread environment.
Time complexity is another crucial concept to understand. If you want to go deeper into it, read the Big(O) Notation article.
String Encodings What to Use?
As mentioned before, the only way for computers to understand and communicate is by translating texts to numbers or bytes. This is called encoding and decoding. There are many characters in the world such as Latin, Japanese, Chinese, and so on.
Unicode is one of the more important encodings since it can encode and decode any character in the world. Unicode can use 1 to 4 bytes and can also represent almost all characters in the world. The Unicode encoding uses hexadecimal numbers too. You can explore all the Unicode characters in the following link: https://symbl.cc/en/unicode/blocks/basic-latin.
If you take a look at the symbols, you will notice that the letter “A” is represented by U+0041, and “B” is U+0042 respectively.
Unicode encodes characters with UTF-8 (Unicode Transformation Format-8), UCS-2, and UTF-16. UTF-8 is the most popular encoding in the world having 97.8% of all web pages.
If you open an IDE such as IntelliJ, you will notice that the default encoding there is UTF-8. UTF-8 can fully represent the ASCII characters and has the capability of using emojis also for example.
Another difference is that while ASCII can use only one byte, UTF-8 can use up to 6 bytes and encodes Latin, Cyrillic, Arabic, Chinese, Japanese languages. UTF-16 is another popular encoding capable of encoding all 1,112,064 valid code points of Unicode. But as it has a greater capacity it also uses more memory, therefore, that’s a good reason to use UTF-8 instead.
There is also UTF-32 which uses exactly a fixed width of 4 bytes (32 bits) per code point. It covers all possible characters but uses a large amount of memory.
Other than Unicode, ASCII, UTF-8, UTF-16, and UTF-32 there are many other encodings that are not so relevant (unless there is a very specific problem to be solved) but it’s important to know they exist.
Another encoding that is used quite often is Base64 for transmitting information through HTML and email. It’s used to encode binary data into ASCII characters.
Also, there are many other encodings for different languages around the world such as: ISO 8859-1 Western Europe, Windows-1253 for Greek, JIS X 0213 for Japanese characters, GB 2312 for Chinese characters, and so on. It’s not necessary to know all of them, it’s good to know where to look for in case it’s necessary. If you want to check all encodings, take a look at this character encoding page.
Summary
- String behind the scenes store an array of bytes.
- String in Java is immutable, meaning that it’s not possible to change the value directly.
- StringBuilder and StringBuffer is a mutable types of String that won’t create lots of objects.
- When concatenating an immutable String a new array has to be created and then the String has to be copied.
- String can be transformed to the code from the ASCII table and vice-versa.
- There are extensions from ASCII such as UTF-8.
- ASCII includes only 128 characters including letters, numbers, and punctuation marks.
- UTF-8 has retro-compatibility with the ASCII table and is the most popular encoding nowadays.





